





recién La inteligencia artificial de la naturaleza El estudio investigó la eficacia de los clasificadores de inteligencia artificial (IA) basados en voz para predecir el estado de infección por coronavirus 2 (SARS-CoV-2) de la neumonía asiática. El SARS-CoV-2 es el organismo causante de la pandemia de la enfermedad por coronavirus 2019 (COVID-19).
Estancia: Los clasificadores de IA basados en voz no muestran evidencia de mejorar la detección de COVID-19 en comparación con herramientas simples de detección de síntomas. Crédito de la imagen: Aleasandra Post/Shutterstock
fondo
Dado que la infección por SARS-CoV-2 puede causar síntomas y ser asintomática, es importante desarrollar pruebas precisas para evitar la cuarentena general de la población. Estudios anteriores revelaron que los clasificadores basados en IA entrenados con datos de audio respiratorio pueden identificar el estado del SARS-CoV-2.
Aunque estos estudios han indicado la eficacia de los clasificadores basados en IA, han surgido varios desafíos al aplicarlos en entornos del mundo real. Algunos de los factores que oscurecieron las aplicaciones de la clasificación basada en IA fueron los sesgos de muestreo, los datos inciertos sobre el estado de COVID-19 de los participantes y el retraso entre la infección y la grabación de audio. Es necesario determinar si los biomarcadores acústicos de COVID-19 son exclusivos de la infección por SARS-CoV-2 o son señales de confusión inapropiadas.
Sobre el estudio
El estudio actual se centró en determinar si los clasificadores de audio se pueden utilizar con precisión para detectar COVID-19. Se utilizó un extenso conjunto de datos de PCR asociado con el cribado acústico de COVID-19 (ABCS). En este estudio, se invitó a participantes del programa de Evaluación en tiempo real de la transmisión comunitaria (REACT) y del servicio Test and Trace (T+T) del Servicio Nacional de Salud (NHS). Todos los datos demográficos relevantes se extrajeron de los registros T+T/REACT.
Se pidió a los participantes que completaran preguntas de la encuesta y grabaran cuatro clips de audio. Para las grabaciones de audio, se les pidió que leyeran una frase específica, seguida de tres exhalaciones consecutivas, emitiendo el sonido «ha». Además, se pidió a los participantes que registraran la tos forzada una y tres veces consecutivas. Todas las grabaciones están documentadas en formato wav. Se evaluó la calidad de las grabaciones de audio y se eliminaron 5.157 grabaciones debido a problemas de calidad.
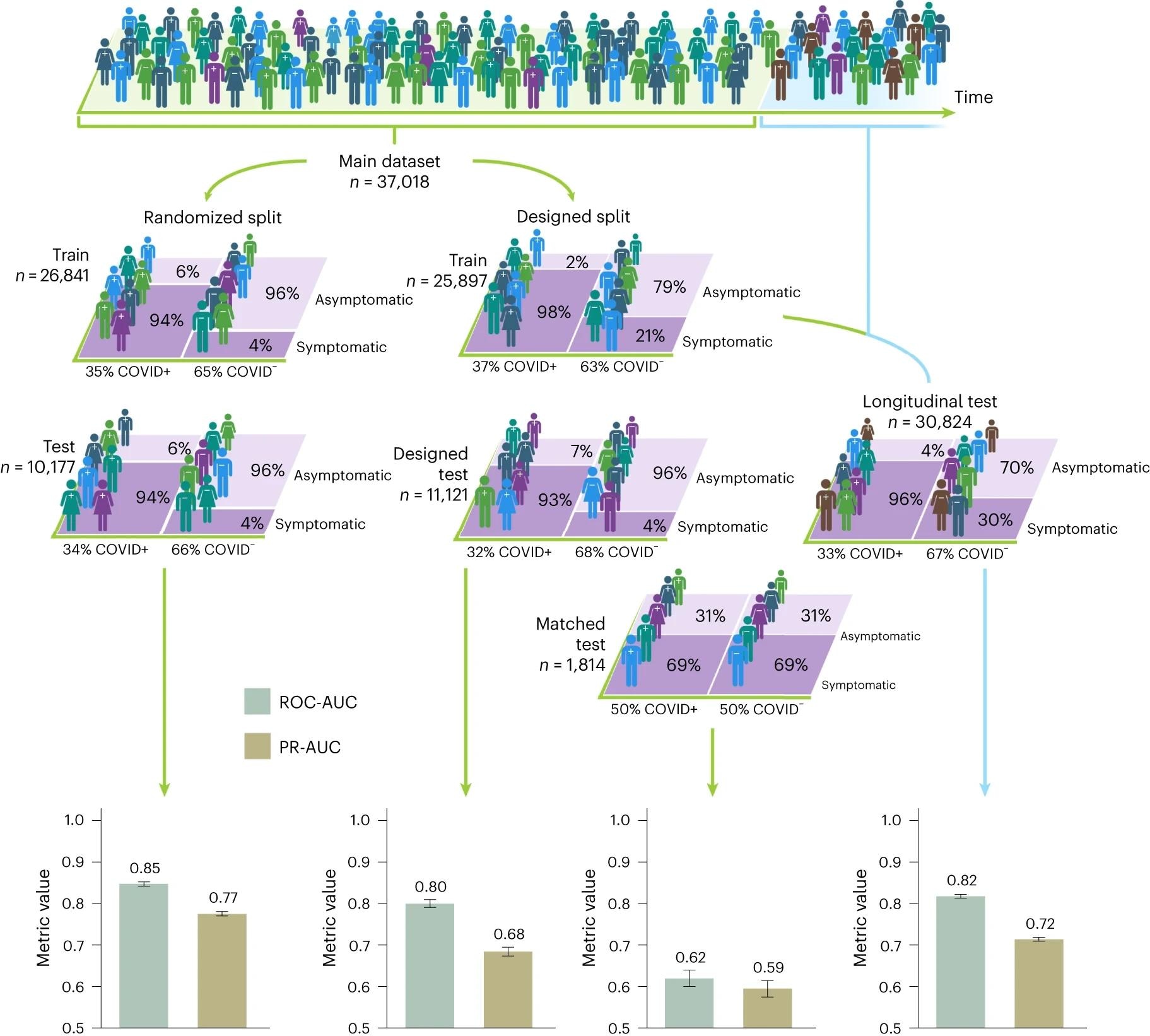 Las figuras humanas representan a los participantes del estudio y su correspondiente estado de infección por COVID-19, con diferentes colores que representan diferentes rasgos o síntomas demográficos. Cuando los participantes se dividen aleatoriamente en conjuntos de entrenamiento y prueba, los modelos divididos aleatoriamente funcionan bien en la detección de COVID-19, logrando AUC de más de 0,8; Sin embargo, se observa que el rendimiento del conjunto de pruebas idéntico cae a un AUC estimado entre 0,60 y 0,65, donde un AUC de 0,5 representa una clasificación aleatoria. El rendimiento de clasificación inflado también se observa en conjuntos de pruebas de distribución diseñados geométricamente, como: el conjunto de pruebas personalizado, en el que solo aparece una selección de grupos demográficos en el conjunto de pruebas, y el conjunto de pruebas longitudinal, en el que no hay superposición en el conjunto de pruebas. . Tiempo de introducción entre el entrenamiento y los casos de prueba. Se muestran los intervalos de confianza del 95% calculados mediante el método de aproximación normal, junto con los n números correspondientes para el tren y los conjuntos de prueba.
Las figuras humanas representan a los participantes del estudio y su correspondiente estado de infección por COVID-19, con diferentes colores que representan diferentes rasgos o síntomas demográficos. Cuando los participantes se dividen aleatoriamente en conjuntos de entrenamiento y prueba, los modelos divididos aleatoriamente funcionan bien en la detección de COVID-19, logrando AUC de más de 0,8; Sin embargo, se observa que el rendimiento del conjunto de pruebas idéntico cae a un AUC estimado entre 0,60 y 0,65, donde un AUC de 0,5 representa una clasificación aleatoria. El rendimiento de clasificación inflado también se observa en conjuntos de pruebas de distribución diseñados geométricamente, como: el conjunto de pruebas personalizado, en el que solo aparece una selección de grupos demográficos en el conjunto de pruebas, y el conjunto de pruebas longitudinal, en el que no hay superposición en el conjunto de pruebas. . Tiempo de introducción entre el entrenamiento y los casos de prueba. Se muestran los intervalos de confianza del 95% calculados mediante el método de aproximación normal, junto con los n números correspondientes para el tren y los conjuntos de prueba.
Resultados
En este estudio, se recopiló un conjunto de datos acústicos respiratorios de 67.842 individuos. De ellos, 23.514 personas dieron positivo por COVID-19. Todos los datos estaban vinculados a los resultados de las pruebas de PCR. Cabe señalar que se reclutó un mayor número de participantes negativos a COVID-19 en las seis rondas REACT en comparación con el canal T+T.
El conjunto de datos considerado en este estudio mostró una cobertura prometedora en toda Inglaterra. No se observó asociación significativa entre la ubicación geográfica y el caso de COVID-19. El mayor nivel de desequilibrio debido al Covid-19 se encontró en Cornualles. Un estudio anterior informó un sesgo de reclutamiento en ABCS, especialmente relacionado con la edad, el idioma y el género, tanto en los datos de entrenamiento como en los conjuntos de pruebas. A pesar de este sesgo, el conjunto de datos de entrenamiento estaba equilibrado por edad y género en los subgrupos positivos y negativos de COVID-19.
De acuerdo con estudios anteriores, el análisis no ajustado realizado en este estudio mostró que los clasificadores de IA pueden predecir el estado de COVID-19 con alta precisión. Sin embargo, cuando se compararon los factores de confusión medidos, se observó un desempeño deficiente de los clasificadores de IA en la detección de casos de SARS-CoV-2.
Con base en los resultados, el presente estudio propuso algunas pautas para corregir el efecto del sesgo de reclutamiento para estudios futuros. Algunas recomendaciones se enumeran a continuación:
- Las muestras de audio almacenadas en repositorios deben incluir detalles de los criterios de reclutamiento del estudio. Además, se debe documentar la información relevante para las personas, incluido su sexo, edad, hora de la prueba de COVID-19, síntomas de SARS-CoV-2 y su ubicación, junto con una grabación de audio.
- Todos los factores de confusión deben identificarse y combinarse para ayudar a controlar el sesgo de contratación.
- El diseño experimental debe desarrollarse teniendo en cuenta los posibles sesgos. En la mayoría de los casos, la coincidencia de datos reduce el tamaño de la muestra. Los estudios observacionales reclutan participantes con énfasis en maximizar la posibilidad de hacer coincidir los factores de confusión medidos.
- Los valores predictivos de los clasificadores deben compararse con los resultados del protocolo estándar.
- Es necesario evaluar la precisión predictiva de los clasificadores de IA. Sin embargo, la precisión, la sensibilidad y la especificidad predictivas varían según la población objetivo.
- La utilidad de los clasificadores debe evaluarse para cada resultado de prueba.
- Se debe realizar un estudio de replicación en grupos aleatorios. Además, los estudios experimentales deben realizarse en entornos del mundo real basados en la utilidad de un dominio específico.
Conclusiones
El estudio actual tuvo limitaciones, incluida la posibilidad de posibles factores de confusión no medidos en los canales de reclutamiento REACT y T+T. Por ejemplo, se realizó una prueba de PCR para COVID-19 varios días después del autoexamen de síntomas. Por el contrario, las pruebas de PCR en REACT se realizaron en una fecha predeterminada, independientemente de la aparición de los síntomas. A pesar de coincidir con la mayoría de los factores de confusión, existe la posibilidad de que se produzca una variación predictiva residual.
A pesar de las limitaciones, este estudio destaca la necesidad de desarrollar procedimientos rigurosos de evaluación del aprendizaje automático para obtener resultados imparciales. Además, el estudio reveló que los factores de confusión son difíciles de detectar y controlar en muchas aplicaciones de IA.
Referencia de la revista:
- Coppock, H. y col. (2024) Los clasificadores de IA basados en voz no muestran evidencia de una mejor detección de COVID-19 en comparación con herramientas simples de detección de síntomas. La inteligencia artificial de la naturaleza. 1-14. doi: 10.1038/s42256-023-00773-8, https://www.nature.com/articles/s42256-023-00773-8

«Propenso a ataques de apatía. Explorador de aspirantes. Analista ávido. Fanático de Internet. Comunicador»
More Stories
Se ha encontrado evidencia del Planeta 9 en cuerpos helados que pasan cerca de Neptuno
La investigación sobre hidruros supera los límites de la superconductividad práctica y accesible
Yokogawa está ayudando a revolucionar la ciencia de los lípidos unicelulares