




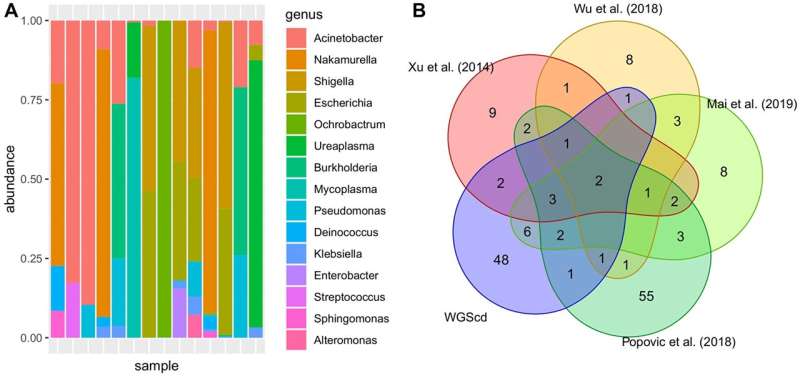
Las bacterias más abundantes se encuentran en la cistoscopia. En (a), la abundancia relativa del género entre las muestras. En (B), diagrama de Venn de la presencia/ausencia: perfil metagenómico de tejidos de cáncer de vejiga obtenidos a partir de datos capturados por secuenciación del genoma completo (WGScd) en comparación con búsquedas bibliográficas del perfil metagenómico de cáncer de vejiga en orina obtenido a partir de la secuenciación de amplicón rRNA 16s. Los datos de taxones se convirtieron a género porque no todos los trabajos proporcionaron resultados para el análisis de especies. se le atribuye: Oncotarget (2022). DOI: 10.18632/oncotarget.28308
La investigación del cáncer ha mejorado drásticamente en los últimos años, principalmente debido a la tecnología de secuenciación de próxima generación (NGS). Así, se ha generado una gran cantidad de datos genómicos y transcriptómicos. En la mayoría de los casos, los datos necesarios se utilizan con fines de investigación y las lecturas no deseadas se descartan. Sin embargo, estos datos eliminados contienen información relevante. Con el objetivo de probar esta hipótesis, los investigadores obtuvieron datos genómicos y transcriptómicos de conjuntos de datos públicos.
En una nueva perspectiva de investigación publicada en Oncotarget, investigadores del Instituto Metrópole Digital de la Universidade Federal do Rio Grande do Norte, el Núcleo de Pesquisas em Oncologia y el Instituto de Ciências Biológicas de la Universidade Federal do Pará utilizaron herramientas metagenómicas para explorar datos genómicos del cáncer; Se usaron anotaciones adicionales para explorar los ncRNA expresados diferencialmente de los experimentos de miRNA, y también se examinaron las variantes que flanquean las muestras de tumores de los experimentos de RNA-seq.
Aquí, mostramos estrategias potenciales para aprovechar la información fuera del objetivo generada por investigaciones de cáncer de alto rendimiento.
En todos los análisis, se obtuvieron nuevos datos: a partir de datos de secuencias de ADN, las clasificaciones de microbiomas tuvieron un rendimiento comparable a la investigación metagenómica ad hoc; A partir de los datos de miRNA-seq, se encontraron más sncRNA expresados diferencialmente; Y en datos tumorales y adyacentes a tejido tumoral se encontraron variantes somáticas.
Estos resultados indican que los datos inexplorados de los ensayos de NGS pueden ayudar a dilucidar la carcinogénesis y descubrir biomarcadores putativos con aplicaciones clínicas. Se deben considerar investigaciones adicionales para el diseño experimental, brindando oportunidades para la optimización de datos y ahorrando tiempo y recursos al tiempo que otorga acceso a múltiples vistas genómicas de la misma muestra y ejecución experimental.
«En conjunto, nuestros resultados refuerzan la hipótesis de que se puede extraer información adicional abundante y potencialmente útil de NGS. Además, una investigación integrada de toda la información disponible debería proporcionar una interpretación más amplia y sólida del escenario molecular de cada experimento», concluyen los investigadores. .
Fabiano Cordero Moreira et al., Tesoros de la basura en la investigación del cáncer, disponible aquí. Oncotarget (2022). DOI: 10.18632/oncotarget.28308
Proporcionado por Oncotarget
La frase: Equipo de investigación explora ‘tesoros’ de datos desechados en la investigación del cáncer (23 de noviembre de 2022) Obtenido el 23 de noviembre de 2022 de https://medicalxpress.com/news/2022-11-team-explores-treasures-discarded-cancer.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin permiso por escrito. El contenido se proporciona únicamente con fines informativos.

«Propenso a ataques de apatía. Explorador de aspirantes. Analista ávido. Fanático de Internet. Comunicador»
More Stories
¿Júpiter tiene anillos? Sí, lo es
El efecto de la dieta sobre las bacterias intestinales proporciona nuevas pistas en el tratamiento de la enfermedad de Parkinson
La línea de luz IRIS en BESSY II obtiene una nueva estación final para espectroscopía a nanoescala