



Estabilidad AI Ltd. hoy pie Una nueva versión de Static Audio, su sistema de inteligencia artificial para crear clips de audio, ofrece un conjunto de funciones muy ampliado.
La versión original de la IA. Apareció por primera vez Septiembre pasado. Stable Audio 1.0, como se conoce al modelo de primera generación, puede crear archivos de audio de hasta 90 segundos de duración. El modelo Stable Audio 2.0 lanzado hoy por Stability AI puede crear pistas de hasta el doble de duración con más personalizaciones proporcionadas por el usuario.
La iteración anterior del sistema generaba audio basado en indicaciones de texto. Mientras tanto, Stable Audio 2.0 puede acomodar no sólo texto sino también clips de audio existentes proporcionados por el usuario. La IA puede hacer coincidir el patrón de sonido que crea con esos clips, lo que permite a los clientes alinear con mayor precisión los archivos resultantes según sus requisitos.
Stable Audio 2.0 también ofrece otras mejoras. Stability AI dice que el modelo puede crear «composiciones estructuradas que incluyen una introducción, desarrollo y conclusión». Otra mejora con respecto al sistema de la generación anterior es que Stable Audio 2.0 puede crear efectos de audio.
Las nuevas capacidades son el resultado de una importante actualización de la infraestructura de IA.
Al igual que su predecesor, Stable Audio 2.0 se basa en lo que se llama un diseño de modelo de difusión. Los modelos de difusión son redes neuronales que se utilizan ampliamente para crear archivos multimedia. Lo que los diferencia de otros algoritmos de IA es la forma en que se entrenan: durante el desarrollo, reciben un conjunto de clips de audio que contienen errores y tienen la tarea de restaurar el audio original.
Stable Audio 2.0 utiliza una aplicación especializada de una tecnología conocida como modelo de difusión latente. Al igual que otras redes neuronales, estos modelos se entrenan en un conjunto de datos similar a los archivos que procesarán en producción. Pero antes de que comience el entrenamiento, el conjunto de datos se transforma en una estructura matemática llamada espacio latente que hace que el proceso de desarrollo de la IA sea más eficiente.
El espacio latente contiene sólo los detalles más importantes del conjunto de datos en el que se basa. Se eliminan los detalles menos relevantes, lo que reduce la cantidad total de información que los modelos de IA deben procesar durante el entrenamiento. Esta reducción en el volumen de datos reduce la cantidad de hardware necesario para entrenar la IA, lo que a su vez reduce los costos.
La primera iteración del sonido consonántico también se basó en el modelo de difusión latente. La nueva versión lanzada hoy presenta un mecanismo más eficiente para generar espacios latentes. «Captura características esenciales y las reproduce mientras filtra detalles menos importantes para generaciones más cohesivas», explicó la compañía en una publicación de blog.
Los ingenieros de Stability AI también agregaron una nueva red neuronal basada en la arquitectura Transformer. Esta arquitectura fue desarrollada por Google LLC en 2017 y se utiliza principalmente para crear modelos de lenguaje. El transformador puede tener en cuenta una gran cantidad de información contextual al interpretar un dato, lo que le permite producir resultados más precisos que las redes neuronales anteriores.
«La combinación de estos dos elementos da como resultado un modelo capaz de reconocer y reproducir estructuras a gran escala que son esenciales para composiciones musicales de alta calidad», explica Stability AI.
Stable Audio 2.0 está disponible de forma gratuita para los consumidores a través de un sitio web Creado por la empresa para el modelo. Está previsto que sea accesible a través de la API «pronto». La API permitirá a otras empresas integrar Stable Audio 2.0 en sus aplicaciones.
imagen: desempaquetar
Su voto a favor es importante para nosotros y nos ayuda a mantener el contenido gratuito.
Un clic a continuación respalda nuestra misión de proporcionar contenido gratuito, profundo y relevante.
Únase a nuestra comunidad en YouTube
Únase a una comunidad de más de 15.000 expertos de #CubeAlumni, incluido el director ejecutivo de Amazon.com, Andy Jassy, el fundador y director ejecutivo de Dell Technologies, Michael Dell, el director ejecutivo de Intel, Pat Gelsinger, y muchas más figuras y expertos notables.
gracias

«Defensor de la Web. Geek de la comida galardonado. Incapaz de escribir con guantes de boxeo puestos. Apasionado jugador».
More Stories
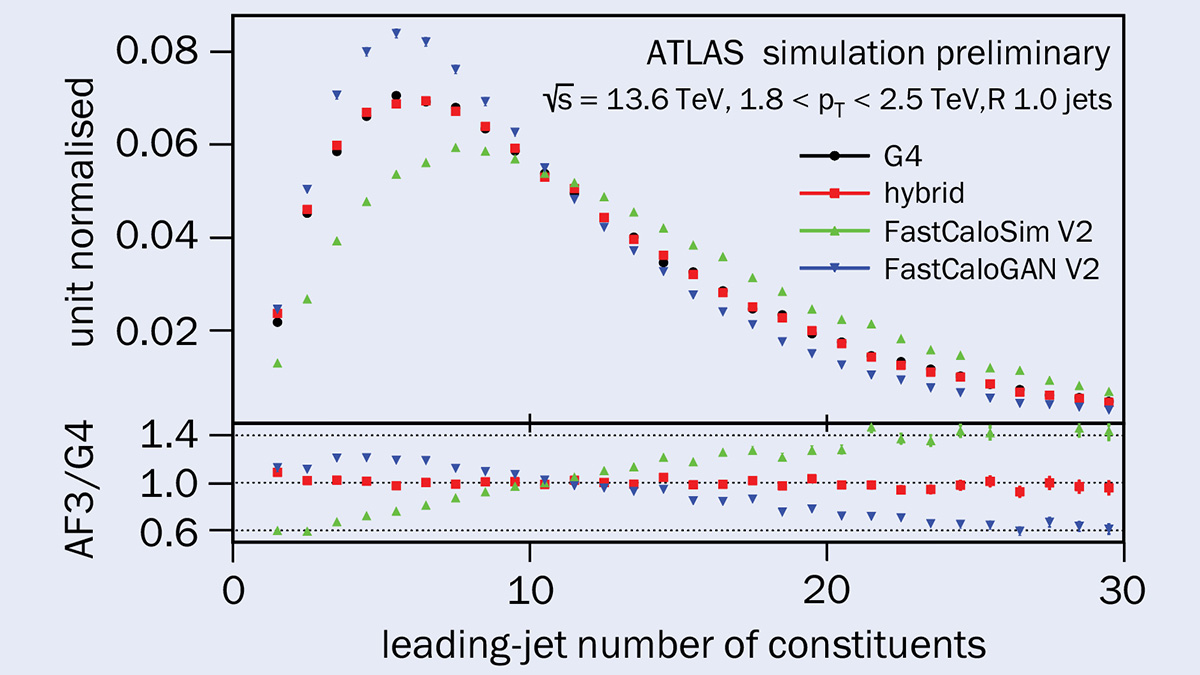
Simulación de eventos de turboalimentación de ATLAS – CERN Courier
Microsoft necesita algo de tiempo para «optimizar» las actualizaciones del software Copilot AI en Windows
Samsung está lanzando una nueva función S24 para impulsar los teléfonos Galaxy más antiguos