




La mayor parte del entrenamiento de redes neuronales profundas se basa en gran medida en el descenso de gradiente, pero elegir el tamaño de paso óptimo para el optimizador es un desafío porque implica un trabajo manual tedioso y propenso a errores.
En NeurIPS 2022 Papel Distinguido Regresión graduada: el potenciador definitivoLos investigadores de MIT CSAIL y Meta presentan una nueva técnica que permite a los optimizadores de descenso de gradiente como SGD y Adam ajustar automáticamente los hiperparámetros. El método no requiere diferenciación manual y se puede apilar iterativamente en varios niveles.

El equipo aborda las limitaciones del optimizador de regresión anterior al habilitar la diferenciación automática (AD), que ofrece tres ventajas principales:
- AD calcula automáticamente las derivadas enteras sin ningún esfuerzo humano adicional.
- Naturalmente, se generaliza a otros hiperparámetros (como el coeficiente de impulso) de forma gratuita.
- AD se puede aplicar no solo a la optimización de hiperparámetros, sino también a hiperparámetros, optimización de hiperparámetros, etc.
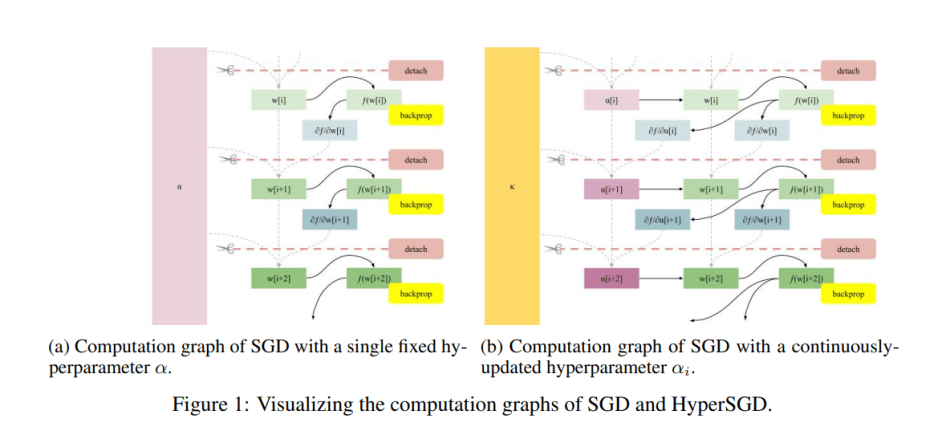
Para habilitar el cálculo automático de gradientes hiperparamétricos, el equipo primero «separa» los pesos del gráfico de cálculo antes de la siguiente iteración del algoritmo de descenso de gradiente, que transforma los pesos en hojas de gráficos al eliminar los bordes entrantes. Este enfoque evita que el gráfico aritmético crezca con cada paso, lo que da como resultado un tiempo al cuadrado y un entrenamiento duro.

El equipo también permite la retropropagación para depositar gradientes con respecto a los pesos y el tamaño del paso al no separar el tamaño del paso del gráfico, sino separar a los padres. Esto conduce a un algoritmo de hiperoptimización completamente automatizado.
Para habilitar automáticamente los gradientes computacionales a través de AD, los investigadores con frecuencia alimentan HyperSGD como optimizador a un optimizador de siguiente nivel, HyperSGD. AD se puede aplicar de esta manera a hiperparámetros, hiperhiperparámetros, hiperhiperhiperparámetros, etc. A medida que crecen estas torres de optimización, se vuelven menos sensibles a la selección inicial de hiperparámetros.

En su estudio experimental, el equipo aplicó SGD sobreoptimizado a optimizadores populares como Adam, AdaGrad y RMSProp. Los resultados muestran que el uso de SGD excesivamente optimizado mejora el rendimiento de referencia por márgenes significativos.
Este trabajo presenta una técnica eficiente que permite a los optimizadores de linaje de degradado ajustar automáticamente sus parámetros de hipervínculo y se pueden apilar iterativamente en varios niveles. Se proporciona una implementación de PyTorch del algoritmo AD para la hoja en el proyecto github.
el papel Regresión graduada: el potenciador definitivo correr AbrirRevisión.
autor: Hécate es | editor: Michael Sarrazín

Sabemos que no quiere perderse ninguna noticia o descubrimiento de investigación. Suscríbete a nuestro popular boletín Sincronización global de IA semanal Para actualizaciones semanales de IA.
More Stories
El código en los datos previos al entrenamiento mejora el rendimiento del LLM en tareas que no son de codificación
Un marco para resolver ecuaciones diferenciales parciales equivalentes puede guiar el procesamiento y la ingeniería de gráficos por computadora
Epiroc ha lanzado una nueva plataforma de perforación de producción de pozos largos